
动态规划穷举的两种视角

动态规划穷举的两种视角
labuladong动态规划穷举的两种视角
读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
| LeetCode | 力扣 | 难度 |
|---|---|---|
| 115. Distinct Subsequencesopen in new window | 115. 不同的子序列open in new window | 🔴 |
| - | 剑指 Offer II 097. 子序列的数目open in new window | 🔴 |
挺久没写动态规划相关的题目了,本文我带大家复习一下动态规划相关问题的一系列解题套路,然后着重讨论一下动态规划穷举时不同视角的问题。
#动态规划解题组合拳
首先,前文 我的刷题心得 讲了,我们刷的算法问题的本质是「穷举」,动态规划问题也不例外,你必须想办法穷举所有可能的解,然后从中筛选出符合题目要求的解。
另外,动态规划问题穷举的过程中会出现重叠子问题导致的冗余计算,所以前文 动态规划核心套路框架 中告诉你如何一步一步把暴力穷举解法优化成效率更高的动态规划解法。
然而,想要写出暴力解需要依据状态转移方程,状态转移方程是动态规划的解题核心,可不是那么容易想出来的。不过,前文 动态规划设计:数学归纳法 告诉你,思考状态转移方程的一个基本方法是数学归纳法,即明确 dp 函数或数组的定义,然后使用这个定义,从已知的「状态」中推导出未知的「状态」。
还没完,比如 高楼扔鸡蛋问题 中对 dp 函数/数组的定义不见得是唯一的,不同的定义会导致状态转移方程发生变化,解题效率也有高低之分,所以我们应该给 dp 函数尽可能想出更合适的定义来解题。
接下来就是本文要着重探讨的问题了:就算 dp 函数/数组的定义相同,如果你使用不同的「视角」进行穷举,效率也不见得是相同的。
关于穷举「视角」的问题,后文 回溯算法穷举视角:子集划分问题 讲了回溯算法中不同的穷举视角导致的不同解法,其实这种视角的切换在动态规划类型问题中依然存在。前文对排列的举例非常有助于你理解穷举视角的问题,这里再简单提一下。
🌟
🌟
#排列问题的两种视角
我们先回顾一下以前学过的排列组合知识:
1、P(n, k)(也有很多书写成 A(n, k))表示从 n 个不同元素中拿出 k 个元素的排列(Permutation/Arrangement);C(n, k) 表示从 n 个不同元素中拿出 k 个元素的组合(Combination)总数。
2、「排列」和「组合」的主要区别在于是否考虑顺序的差异。
3、排列和组合总数的计算公式如下:
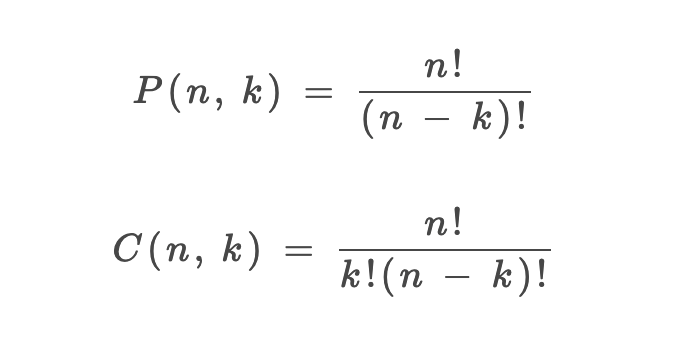
好,现在我问一个问题,这个排列公式 P(n, k) 是如何推导出来的?为了搞清楚这个问题,我需要讲一点组合数学的知识。
排列组合问题的各种变体都可以抽象成「球盒模型」,P(n, k) 就可以抽象成下面这个场景:
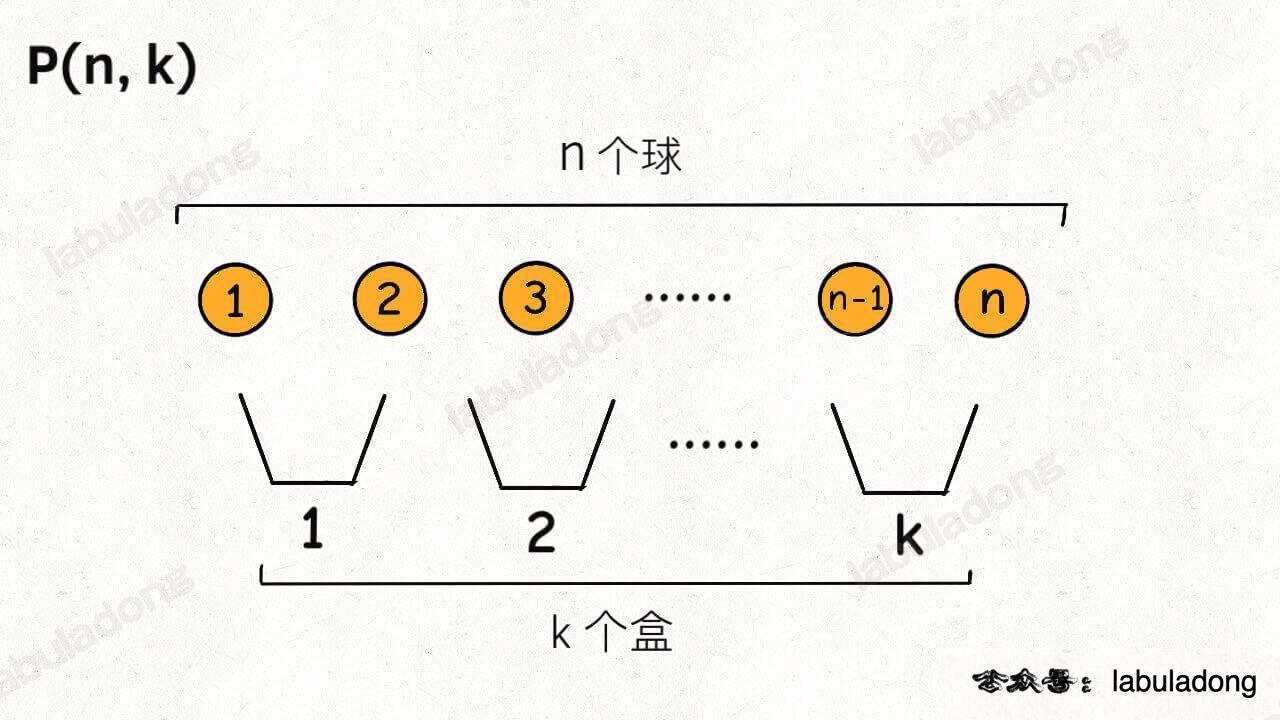
即,将 n 个标记了不同序号的球(标号为了体现顺序的差异),放入 k 个标记了不同序号的盒子中(其中 n >= k,每个盒子最终都装有恰好一个球),共有 P(n, k) 种不同的方法。
现在你来,往盒子里放球,你怎么放?其实有两种视角。
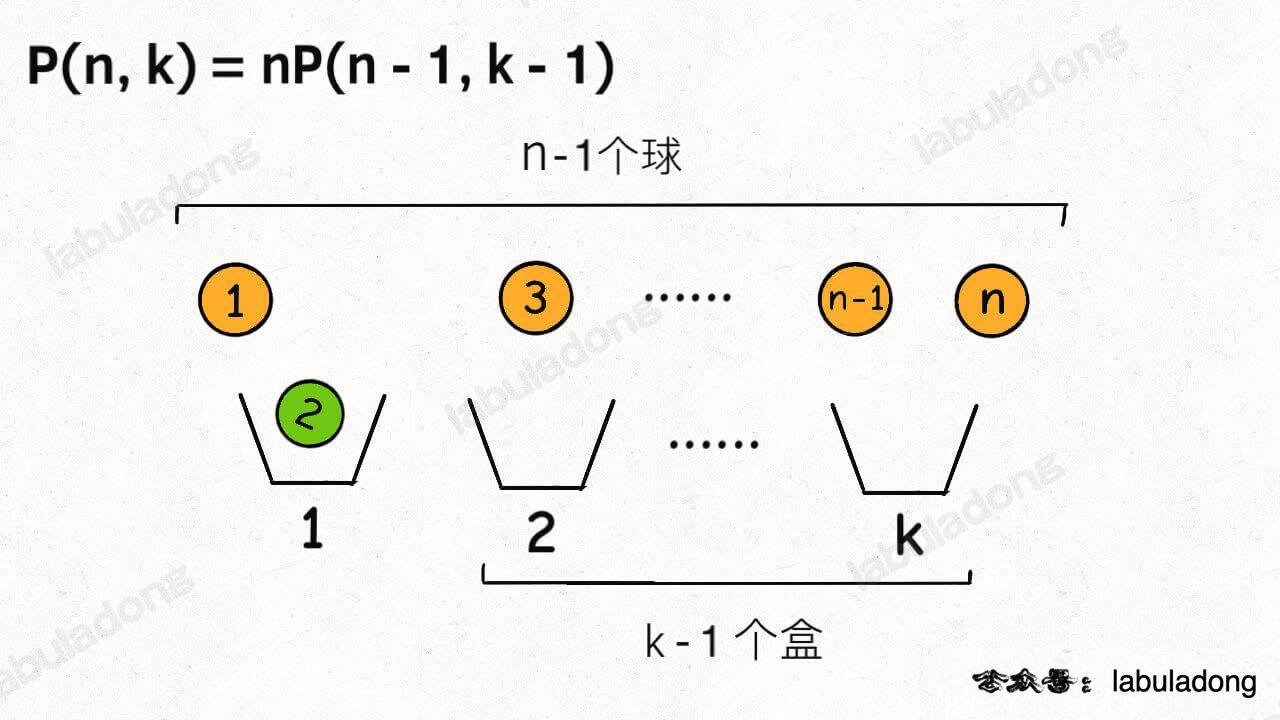
首先,你可以站在盒子的视角,每个盒子必然要选择一个球。
这样,第一个盒子可以选择 n 个球中的任意一个,然后你需要让剩下 k - 1 个盒子在 n - 1 个球中选择:
另外,你也可以站在球的视角,因为并不是每个球都会被装进盒子,所以球的视角分两种情况:
1、第一个球可以不装进任何一个盒子,这样的话你就需要将剩下 n - 1 个球放入 k 个盒子。
2、第一个球可以装进 k 个盒子中的任意一个,这样的话你就需要将剩下 n - 1 个球放入 k - 1 个盒子。
结合上述两种情况,可以得到:

你看,两种视角得到两个不同的递归式,但这两个递归式解开的结果都是我们熟知的阶乘形式:

至于如何解递归式,涉及数学的内容比较多,这里就不做深入探讨了,有兴趣的读者可以自行学习组合数学相关知识。
当然,以上只是纯数学的推导,P(n, k) 的计算结果也仅仅是一个数字,所以以上两种穷举视角从数学上讲没什么差异。但从编程的角度来看,如果让你计算出来所有排列结果,那么两种穷举思路的代码实现可能会产生性能上的差异,因为有的穷举思路难免会使用额外的 for 循环拖慢效率,这也是后文 回溯算法穷举视角:子集划分问题 主要探讨的。
本文不讲回溯算法和排列组合,不过请你记住这个例子,待会会把这种穷举视角的差异运用到动态规划题目当中。
#例题分析
看一下力扣第 115 题「不同的子序列open in new window」:给你输入一个字符串 s 和一个字符串 t,请你计算在 s 的子序列中 t 出现的次数。比如题目给的例子,输入 s = "babgbag", t = "bag",算法返回 5:

函数签名如下:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
int numDistinct(String s, String t); |
你要数一数 s 的子序列中有多少个 t,说白了就是穷举嘛,那么首先想到的就是能不能把原问题分解成规模更小的子问题,然后通过子问题的答案推导出原问题的答案。
首先,我们可以这样定义一个 dp 函数:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
// 定义:s[i..] 的子序列中 t[j..] 出现的次数为 dp(s, i, t, j) |
这道题对 dp 函数的定义很简单直接,题目让你求出现次数,那你就定义函数返回值为出现次数就可以。
有了这个 dp 函数,题目想要的结果是 dp(s, 0, t, 0),base case 也很容易写出来,解法框架如下:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
int numDistinct(String s, String t) { |
好,接下来开始思考如何利用这个 dp 函数将大问题分解成小问题,即如何写出状态转移方程进行穷举。
回顾一下之前讲的排列组合的「球盒模型」,这里是不是很类似?t 中的若干字符就好像若干盒子,s 中的若干字符就好像若干小球,你需要做的就是给所有盒子都装一个小球。所以这里就有两种穷举思路了,分别是站在 t 的视角(盒子选择小球)和站在 s 的视角(小球选择盒子)。
视角一,站在 t 的角度进行穷举:
我们的原问题是求 s[0..] 的所有子序列中 t[0..] 出现的次数,那么可以先看 t[0] 在 s 中的什么位置,假设 s[2], s[6] 是字符 t[0],那么原问题转化成了在 s[3..] 和 s[7..] 的所有子序列中计算 t[1..] 出现的次数。
写成比较偏数学的形式就是状态转移方程:
-- 定义:s[i..] 的子序列中 t[j..] 出现的次数为 dp(s, i, t, j) |
翻译成代码大致就是这个思路:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
// 定义:s[i..] 的子序列中 t[j..] 出现的次数为 dp(s, i, t, j) |
这个思路应该不难理解吧,当然还可以加上备忘录消除重叠子问题,最终解法如下:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution { |
这道题就解决了,不过效率不算很高,我们可以粗略估算一下这个算法的时间复杂度上界,其中 M, N 分别代表 s, t 的长度,算法的「状态」就是 dp 函数参数 i, j 的组合:
带备忘录的动态规划算法的时间复杂度 |
当然,因为 for 循环的复杂度不总是 O(M) 且子问题个数肯定小于 O(MN),所以这是复杂度的粗略上界。不过根据前文 算法时空复杂度使用指南 的描述,这个上界还是说明这个算法的复杂度有些偏高。主要高在哪里呢?对「状态」的穷举已经有了 memo 备忘录的优化,所以 O(MN) 的复杂度是必不可少的,关键问题出在 dp 函数中的 for 循环。
是否可以优化掉 dp 函数中的 for 循环呢?可以的,这就需要另一种穷举视角来解决这个问题。
视角二,站在 s 的角度进行穷举:
我们的原问题是计算 s[0..] 的所有子序列中 t[0..] 出现的次数,可以先看看 s[0] 是否能匹配 t[0],如果不匹配,那没得说,原问题就可以转化为计算 s[1..] 的所有子序列中 t[0..] 出现的次数;
但如果 s[0] 可以匹配 t[0],那么又有两种情况,这两种情况是累加的关系:
1、让 s[0] 匹配 t[0],那么原问题转化为在 s[1..] 的所有子序列中计算 t[1..] 出现的次数。
2、不让 s[0] 匹配 t[0],那么原问题转化为在 s[1..] 的所有子序列中计算 t[0..] 出现的次数。
为啥明明 s[0] 可以匹配 t[0],还不让它俩匹配呢?主要是为了给 s[0] 之后的元素匹配的机会,比如 s = "aab", t = "ab",就有两种匹配方式:a_b 和 _ab。
把以上思路写成状态转移方程:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
// 定义:s[i..] 的子序列中 t[j..] 出现的次数为 dp(s, i, t, j) |
依照这个思路,再加个备忘录消除重叠子问题,可以写出如下解法:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution { |
🎃 代码可视化动画 🎃
这个解法中 dp 函数递归的次数,即状态 i, j 的不同组合的个数为 O(MN),而 dp 函数本身没有 for 循环,即时间复杂度为 O(1),所以算法总的时间复杂度就是 O(MN),比刚才的解法要好一些,你提交这个解法代码,耗时明显比刚才的解法少一些。
至此,这道题就分析完了。我们分别站在 t 的视角和 s 的视角运用 dp 函数的定义进行穷举,得出两种完全不同但都是正确的状态转移逻辑,不过两种逻辑在代码实现上有效率的差异。
那么不妨进一步思考一下,什么样的动态规划题目可能产生「穷举视角」上的差异?换句话说,什么样的动态规划问题能够抽象成经典的「球盒模型」呢?如果你有思考,欢迎留言和我探讨。

















