算法算法转载二叉堆详解实现优先级队列
labuladong二叉堆详解实现优先级队列
二叉堆(Binary Heap)没什么神秘,性质比二叉搜索树 BST 还简单。
其主要操作就两个,sink(下沉)和 swim(上浮),用以维护二叉堆的性质。其主要应用有两个,首先是一种排序方法「堆排序」,第二是一种很有用的数据结构「优先级队列」。
那么本文以实现优先级队列(Priority Queue)为例,来讲讲一下二叉堆怎么运作的。
#一、二叉堆概览
首先,二叉堆和二叉树有啥关系呢,为什么人们总是把二叉堆画成一棵二叉树?
因为,二叉堆在逻辑上其实是一种特殊的二叉树(完全二叉树),只不过存储在数组里。一般的链表二叉树,我们操作节点的指针,而在数组里,我们把数组索引作为指针:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
int parent(int root) {
return root / 2;
}
int left(int root) {
return root * 2;
}
int right(int root) {
return root * 2 + 1;
}
|
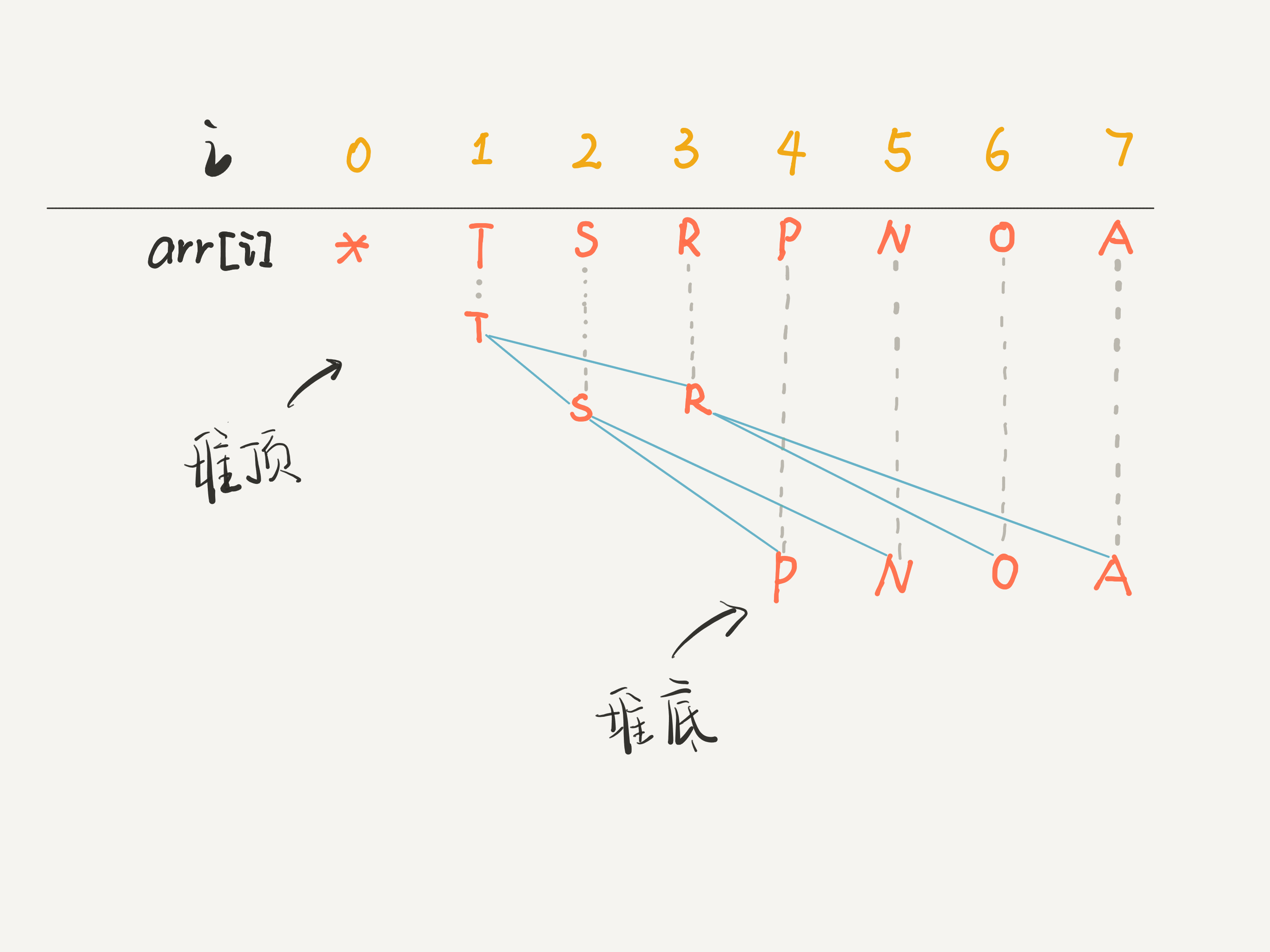
画个图你立即就能理解了,比如 arr 是一个字符数组,注意数组的第一个索引 0 空着不用:

你看到了,因为这棵二叉树是「完全二叉树」,所以把 arr[1] 作为整棵树的根的话,每个节点的父节点和左右孩子的索引都可以通过简单的运算得到,这就是二叉堆设计的一个巧妙之处。
为了方便讲解,下面都会画的图都是二叉树结构,相信你能把树和数组对应起来。
二叉堆还分为最大堆和最小堆。最大堆的性质是:每个节点都大于等于它的两个子节点。类似的,最小堆的性质是:每个节点都小于等于它的子节点。
两种堆核心思路都是一样的,本文以最大堆为例讲解。
对于一个最大堆,根据其性质,显然堆顶,也就是 arr[1] 一定是所有元素中最大的元素。
#二、优先级队列概览
优先级队列这种数据结构有一个很有用的功能,你插入或者删除元素的时候,元素会自动排序,这底层的原理就是二叉堆的操作。
数据结构的功能无非增删查改,优先级队列有两个主要 API,分别是 insert 插入一个元素和 delMax 删除最大元素(如果底层用最小堆,那么就是 delMin,删除最小元素)。
注
刚才说到二叉堆本质上是一棵二叉树,而优先级队列这种数据结构底层是二叉堆,那么为啥它的名字又和「队列」扯上了关系呢?
因为优先级队列的操作和队列比较像。普通队列有个从队尾插入元素,从队头移出元素,出队顺序就是入队的时间顺序;你也可以认为优先级队列是一种特殊的队列,从队尾插入元素,从队头移出元素,只不过出队顺序是按照元素的大小顺序。
这么一看,是不是觉得这种数据结构有队列内味儿了?
下面我们实现一个简化的优先级队列,先看下代码框架:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
public class MaxPQ
<Key extends Comparable<Key>> {
private Key[] pq;
private int size = 0;
public MaxPQ(int cap) {
pq = (Key[]) new Comparable[cap + 1];
}
public Key max() {
return pq[1];
}
public void insert(Key e) {...}
public Key delMax() {...}
private void swim(int x) {...}
private void sink(int x) {...}
private void swap(int i, int j) {
Key temp = pq[i];
pq[i] = pq[j];
pq[j] = temp;
}
private boolean less(int i, int j) {
return pq[i].compareTo(pq[j]) < 0;
}
}
|
提示
这里用到 Java 的泛型,Key 可以是任何一种可比较大小的数据类型(实现了 compareTo 方法),比如 Integer 等类型。
当然,你自己练习时可以适度变通,比如说在构造函数中传入一个比较函数,这样就可以实现自定义排序逻辑了。
我这里为了简化,就实现一个最大堆 MaxPQ,即每次删除都是队列中最大的元素。
空出来的四个方法是二叉堆和优先级队列的奥妙所在,下面用图文来逐个理解。
#三、实现 swim 和 sink
为什么要有上浮 swim 和下沉 sink 的操作呢?为了维护二叉堆结构。
我们要讲的是最大堆,每个节点都比它的两个子节点大,但是在插入元素和删除元素时,难免破坏堆的性质,这就需要通过这两个操作来恢复堆的性质了。
对于最大堆,会破坏堆性质的有两种情况:
1、如果某个节点 A 比它的子节点(中的一个)小,那么 A 就不配做父节点,应该下去,下面那个更大的节点上来做父节点,这就是对 A 进行下沉。
2、如果某个节点 A 比它的父节点大,那么 A 不应该做子节点,应该把父节点换下来,自己去做父节点,这就是对 A 的上浮。
当然,错位的节点 A 可能要上浮(或下沉)很多次,才能到达正确的位置,恢复堆的性质。所以代码中肯定有一个 while 循环。
细心的读者也许会问,这两个操作不是互逆吗,所以上浮的操作一定能用下沉来完成,为什么我还要费劲写两个方法?
是的,操作是互逆等价的,但是最终我们的操作只会在堆底和堆顶进行(等会讲原因),显然堆底的「错位」元素需要上浮,堆顶的「错位」元素需要下沉。
上浮的代码实现:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
public class MaxPQ <Key extends Comparable<Key>> {
private void swim(int x) {
while (x > 1 && less(parent(x), x)) {
swap(parent(x), x);
x = parent(x);
}
}
}
|
画个 GIF 看一眼就明白了:
下沉的代码实现:
下沉比上浮略微复杂一点,因为上浮某个节点 A,只需要 A 和其父节点比较大小即可;但是下沉某个节点 A,需要 A 和其两个子节点比较大小,如果 A 不是最大的就需要调整位置,要把较大的那个子节点和 A 交换。
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
public class MaxPQ <Key extends Comparable<Key>> {
private void sink(int x) {
while (left(x) <= size) {
int max = left(x);
if (right(x) <= size && less(max, right(x)))
max = right(x);
if (less(max, x)) break;
swap(x, max);
x = max;
}
}
}
|
画个 GIF 看下就明白了:
至此,二叉堆的主要操作就讲完了,一点都不难吧,代码加起来也就十行。明白了 sink 和 swim 的行为,下面就可以实现优先级队列了。
#四、实现 delMax 和 insert
这两个方法就是建立在 swim 和 sink 上的。
insert 方法先把要插入的元素添加到堆底的最后,然后让其上浮到正确位置。
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
public class MaxPQ <Key extends Comparable<Key>> {
public void insert(Key e) {
size++;
pq[size] = e;
swim(size);
}
}
|
delMax 方法先把堆顶元素 A 和堆底最后的元素 B 对调,然后删除 A,最后让 B 下沉到正确位置。
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
public class MaxPQ <Key extends Comparable<Key>> {
public Key delMax() {
Key max = pq[1];
swap(1, size);
pq[size] = null;
size--;
sink(1);
return max;
}
}
|
至此,一个优先级队列就实现了,插入和删除元素的时间复杂度为 O(logK),K 为当前二叉堆(优先级队列)中的元素总数。因为我们时间复杂度主要花费在 sink 或者 swim 上,而不管上浮还是下沉,最多也就树(堆)的高度,也就是 log 级别。
#五、最后总结
二叉堆就是一种完全二叉树,所以适合存储在数组中,而且二叉堆拥有一些特殊性质。
二叉堆的操作很简单,主要就是上浮和下沉,来维护堆的性质(堆有序),核心代码也就十行。
优先级队列是基于二叉堆实现的,主要操作是插入和删除。插入是先插到最后,然后上浮到正确位置;删除是调换位置后再删除,然后下沉到正确位置。核心代码也就十行。
也许这就是数据结构的威力,简单的操作就能实现巧妙的功能,真心佩服发明二叉堆算法的人!
最后,更多二叉堆/优先级队列相关的题目练习见 二叉堆(优先级队列)的经典习题open in new window。
经典练习题
二叉堆的主要应用是优先级队列,而优先级队列的特色是动态排序,插入的元素可以自动维护正确的顺序。当然,后文讲的 二叉搜索树open in new window 也可以做到动态排序,优先级队列的限制是只能从队头和队尾操作元素。
一般来说,用到优先级队列的题目主要分两类,一类是合并多个有序链表这类题,另一类是寻找第 k 个最大元素这类题,我们分别来看。
先来看第一类,合并有序链表这样的题目:
给你一个链表数组,每个链表都已经按升序排列,请你将这些链表合并成一个升序链表,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
|
#基本思路
本文有视频版:链表双指针技巧全面汇总open in new window
21. 合并两个有序链表open in new window 的延伸,利用 优先级队列(二叉堆)open in new window 进行节点排序即可。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
if (lists.length == 0) return null;
ListNode dummy = new ListNode(-1);
ListNode p = dummy;
PriorityQueue<ListNode> pq = new PriorityQueue<>(
lists.length, (a, b)->(a.val - b.val));
for (ListNode head : lists) {
if (head != null)
pq.add(head);
}
while (!pq.isEmpty()) {
ListNode node = pq.poll();
p.next = node;
if (node.next != null) {
pq.add(node.next);
}
p = p.next;
}
return dummy.next;
}
}
|
给定两个以 升序排列 的整数数组 nums1 和 nums2, 以及一个整数 k。
定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2。
请找到和最小的 k 个数对 (u1,v1), (u2,v2) … (uk,vk)。
示例 1:
输入:nums1 = [1,7,11], nums2 = [2,4,6], k = 3
输出:[1,2],[1,4],[1,6]
解释:返回序列中的前 3 对数:
[1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6]
|
#基本思路
这道题其实是前文 单链表的六大解题套路open in new window 中讲过的 23. 合并K个升序链表open in new window 的变体。
怎么把这道题变成合并多个有序链表呢?就比如说题目输入的用例:
nums1 = [1,7,11], nums2 = [2,4,6]
|
组合出的所有数对儿这就可以抽象成三个有序链表:
[1, 2] -> [1, 4] -> [1, 6]
[7, 2] -> [7, 4] -> [7, 6]
[11, 2] -> [11, 4] -> [11, 6]
|
这三个链表中每个元素(数对之和)是递增的,所以就可以按照 23. 合并K个升序链表open in new window 的思路来合并,取出前 k 个作为答案即可。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public List<List<Integer>> kSmallestPairs(int[] nums1, int[] nums2, int k) {
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> {
return (a[0] + a[1]) - (b[0] + b[1]);
});
for (int i = 0; i < nums1.length; i++) {
pq.offer(new int[]{nums1[i], nums2[0], 0});
}
List<List<Integer>> res = new ArrayList<>();
while (!pq.isEmpty() && k > 0) {
int[] cur = pq.poll();
k--;
int next_index = cur[2] + 1;
if (next_index < nums2.length) {
pq.add(new int[]{cur[0], nums2[next_index], next_index});
}
List<Integer> pair = new ArrayList<>();
pair.add(cur[0]);
pair.add(cur[1]);
res.add(pair);
}
return res;
}
}
|
给你一个 n x n 矩阵 matrix,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素。
请注意,它是 排序后 的第 k 小元素,而不是第 k 个 不同的元素。
你必须找到一个内存复杂度优于 O(n2) 的解决方案。
示例 1:
输入:matrix = [[1,5,9],[10,11,13],[12,13,15]], k = 8
输出:13
解释:矩阵中的元素为 [1,5,9,10,11,12,13,13,15],第 8 小元素是 13
|
#基本思路
这道题其实是前文 单链表的六大解题套路open in new window 中讲过的 23. 合并K个升序链表open in new window 的变体。
矩阵中的每一行都是排好序的,就好比多条有序链表,你用优先级队列施展合并多条有序链表的逻辑就能找到第 k 小的元素了。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public int kthSmallest(int[][] matrix, int k) {
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> {
return a[0] - b[0];
});
for (int i = 0; i < matrix.length; i++) {
pq.offer(new int[]{matrix[i][0], i, 0});
}
int res = -1;
while (!pq.isEmpty() && k > 0) {
int[] cur = pq.poll();
res = cur[0];
k--;
int i = cur[1], j = cur[2];
if (j + 1 < matrix[i].length) {
pq.add(new int[]{matrix[i][j + 1], i, j + 1});
}
}
return res;
}
}
|
超级丑数 是一个正整数,并满足其所有质因数都出现在质数数组 primes 中。给你一个整数 n 和一个整数数组 primes,返回第 n 个 超级丑数。
示例 1:
输入:n = 12, primes = [2,7,13,19]
输出:32
解释:给定长度为 4 的质数数组 primes = [2,7,13,19],前 12 个超级丑数序列为:[1,2,4,7,8,13,14,16,19,26,28,32]。
|
#基本思路
这题是 264. 丑数 IIopen in new window 的进阶版,第 264 题是 21. 合并两个有序链表(简单)open in new window 的变体,而这道题是 23. 合并K个升序链表(困难)open in new window 的变体,我在 双指针技巧秒杀七道链表题目open in new window 中都讲过。
你一定要先做下 264 题,注意那里我们抽象出了三条链表,需要 p2, p3, p5 作为三条有序链表上的指针,同时需要 product2, product3, product5 记录指针所指节点的值,用 min 函数计算最小头结点。
这道题相当于输入了 len(primes) 条有序链表,我们不能用 min 函数计算最小头结点了,而是要用优先级队列来计算最小头结点,同时依然要维护链表指针、指针所指节点的值,我们把这些信息用一个三元组来保存。
结合第 23 题的解法逻辑,你应该能够看懂这道题的解法代码了。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public int nthSuperUglyNumber(int n, int[] primes) {
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> {
return a[0] - b[0];
});
for (int i = 0; i < primes.length; i++) {
pq.offer(new int[]{ 1, primes[i], 1 });
}
int[] ugly = new int[n + 1];
int p = 1;
while (p <= n) {
int[] pair = pq.poll();
int product = pair[0];
int prime = pair[1];
int index = pair[2];
if (product != ugly[p - 1]) {
ugly[p] = product;
p++;
}
int[] nextPair = new int[]{ugly[index] * prime, prime, index + 1};
pq.offer(nextPair);
}
return ugly[n];
}
}
|
设计一个简化版的推特 (Twitter),可以让用户实现发送推文,关注/取消关注其他用户,能够看见关注人(包括自己)的最近 10 条推文。
实现 Twitter 类:
void postTweet(int userId, int tweetId) 根据给定的 tweetId 和 userId 创建一条新推文。每次调用此函数都会使用一个不同的 tweetId。List<Integer> getNewsFeed(int userId) 检索当前用户新闻推送中最近 10 条推文的 ID。新闻推送中的每一项都必须是由用户关注的人或者是用户自己发布的推文。推文必须按照时间顺序由最近到最远排序。void follow(int followerId, int followeeId) ID 为 followerId 的用户开始关注 ID 为 followeeId 的用户。void unfollow(int followerId, int followeeId) ID 为 followerId 的用户不再关注 ID 为 followeeId 的用户。
示例:
输入
["Twitter", "postTweet", "getNewsFeed", "follow", "postTweet", "getNewsFeed", "unfollow", "getNewsFeed"]
[[], [1, 5], [1], [1, 2], [2, 6], [1], [1, 2], [1]]
输出
[null, null, [5], null, null, [6, 5], null, [5]]
解释
Twitter twitter = new Twitter();
twitter.postTweet(1, 5); // 用户 1 发送了一条新推文 (用户 id = 1, 推文 id = 5)
twitter.getNewsFeed(1); // 用户 1 的获取推文应当返回一个列表,其中包含一个 id 为 5 的推文
twitter.follow(1, 2); // 用户 1 关注了用户 2
twitter.postTweet(2, 6); // 用户 2 发送了一个新推文 (推文 id = 6)
twitter.getNewsFeed(1); // 用户 1 的获取推文应当返回一个列表,其中包含两个推文,id 分别为 -> [6, 5]。推文 id 6 应当在推文 id 5 之前,因为它是在 5 之后发送的
twitter.unfollow(1, 2); // 用户 1 取消关注了用户 2
twitter.getNewsFeed(1); // 用户 1 获取推文应当返回一个列表,其中包含一个 id 为 5 的推文。因为用户 1 已经不再关注用户 2
|
#基本思路
这道题比较经典,在特定场景下让你设计算法。其难点在于 getNewsFeed 方法,要按照时间线顺序展示所有关注用户的推文,这个方法要用到我在 单链表的六大解题套路open in new window 解决 23. 合并K个升序链表open in new window 的合并多个有序链表的技巧:
你把一个用户发布的所有推文做成一条有序链表(靠近头部的推文是最近发布的),那么只要合并关注用户的推文链表,即可获得按照时间线顺序排序的信息流。
具体看代码吧,我注释比较详细。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Twitter {
int globalTime = 0;
HashMap<Integer, User> idToUser = new HashMap<>();
class Tweet {
private int id;
private int timestamp;
private Tweet next;
public Tweet(int id) {
this.id = id;
this.timestamp = globalTime++;
}
public int getId() {
return id;
}
public int getTimestamp() {
return timestamp;
}
public Tweet getNext() {
return next;
}
public void setNext(Tweet next) {
this.next = next;
}
}
class User {
private int id;
private Tweet tweetHead;
private HashSet<User> followedUserSet;
public User(int id) {
this.id = id;
this.tweetHead = null;
this.followedUserSet = new HashSet<>();
}
public int getId() {
return id;
}
public Tweet getTweetHead() {
return tweetHead;
}
public HashSet<User> getFollowedUserSet() {
return followedUserSet;
}
public boolean equals(User other) {
return this.id == other.id;
}
public void follow(User other) {
followedUserSet.add(other);
}
public void unfollow(User other) {
followedUserSet.remove(other);
}
public void post(Tweet tweet) {
tweet.setNext(tweetHead);
tweetHead = tweet;
}
}
public void postTweet(int userId, int tweetId) {
if (!idToUser.containsKey(userId)) {
idToUser.put(userId, new User(userId));
}
User user = idToUser.get(userId);
user.post(new Tweet(tweetId));
}
public List<Integer> getNewsFeed(int userId) {
List<Integer> res = new LinkedList<>();
if (!idToUser.containsKey(userId)) {
return res;
}
User user = idToUser.get(userId);
Set<User> followedUserSet = user.getFollowedUserSet();
PriorityQueue<Tweet> pq = new PriorityQueue<>((a, b) -> {
return b.timestamp - a.timestamp;
});
if (user.getTweetHead() != null) {
pq.offer(user.getTweetHead());
}
for (User other : followedUserSet) {
if (other.getTweetHead() != null) {
pq.offer(other.tweetHead);
}
}
int count = 0;
while (!pq.isEmpty() && count < 10) {
Tweet tweet = pq.poll();
res.add(tweet.getId());
if (tweet.getNext() != null) {
pq.offer(tweet.getNext());
}
count++;
}
return res;
}
public void follow(int followerId, int followeeId) {
if (!idToUser.containsKey(followerId)) {
idToUser.put(followerId, new User(followerId));
}
if (!idToUser.containsKey(followeeId)) {
idToUser.put(followeeId, new User(followeeId));
}
User follower = idToUser.get(followerId);
User followee = idToUser.get(followeeId);
follower.follow(followee);
}
public void unfollow(int followerId, int followeeId) {
if (!idToUser.containsKey(followerId) || !idToUser.containsKey(followeeId)) {
return;
}
User follower = idToUser.get(followerId);
User followee = idToUser.get(followeeId);
follower.unfollow(followee);
}
}
|
再来看第二类,寻找第 k 个最大元素这类题:
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入:[3,2,1,5,6,4] 和 k = 2
输出:5
|
示例 2:
输入:[3,2,3,1,2,4,5,5,6] 和 k = 4
输出:4
|
#基本思路
二叉堆的解法比较简单,实际写算法题的时候,推荐大家写这种解法。
可以把小顶堆 pq 理解成一个筛子,较大的元素会沉淀下去,较小的元素会浮上来;当堆大小超过 k 的时候,我们就删掉堆顶的元素,因为这些元素比较小,而我们想要的是前 k 个最大元素嘛。
当 nums 中的所有元素都过了一遍之后,筛子里面留下的就是最大的 k 个元素,而堆顶元素是堆中最小的元素,也就是「第 k 个最大的元素」。
二叉堆插入和删除的时间复杂度和堆中的元素个数有关,在这里我们堆的大小不会超过 k,所以插入和删除元素的复杂度是 O(logK),再套一层 for 循环,总的时间复杂度就是 O(NlogK)。
当然,这道题可以有效率更高的解法叫「快速选择算法」,只需要 O(N) 的时间复杂度。
快速选择算法不用借助二叉堆结构,而是稍微改造了快速排序的算法思路,有兴趣的读者可以看详细题解。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public int findKthLargest(int[] nums, int k) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
for (int e : nums) {
pq.offer(e);
if (pq.size() > k) {
pq.poll();
}
}
return pq.peek();
}
}
|
给定一个字符串 s,根据字符出现的 频率 对其进行 降序排序。一个字符出现的 频率 是它出现在字符串中的次数,返回已排序的字符串。如果有多个答案,返回其中任何一个。
示例 1:
输入:s = "tree"
输出:"eert"
解释:'e' 出现两次,'r' 和 't' 都只出现一次。
因此 'e' 必须出现在 'r' 和 't' 之前。此外,"eetr" 也是一个有效的答案。
|
#基本思路
做这道题肯定需要计算每个字符出现的频率,然后你可以用很多种其他方法把字符按照频率排序。我这里用 优先级队列open in new window 来实现排序的效果,详细看代码。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public String frequencySort(String s) {
char[] chars = s.toCharArray();
HashMap<Character, Integer> charToFreq = new HashMap<>();
for (char ch : chars) {
charToFreq.put(ch, charToFreq.getOrDefault(ch, 0) + 1);
}
PriorityQueue<Map.Entry<Character, Integer>>
pq = new PriorityQueue<>((entry1, entry2) -> {
return entry2.getValue().compareTo(entry1.getValue());
});
for (Map.Entry<Character, Integer> entry : charToFreq.entrySet()) {
pq.offer(entry);
}
StringBuilder sb = new StringBuilder();
while (!pq.isEmpty()) {
Map.Entry<Character, Integer> entry = pq.poll();
String part = String.valueOf(entry.getKey()).repeat(entry.getValue());
sb.append(part);
}
return sb.toString();
}
}
|
设计一个找到数据流中第 k 大元素的类(class)。注意是排序后的第 k 大元素,不是第 k 个不同的元素。
请实现 KthLargest 类:
1、KthLargest(int k, int[] nums) 使用整数 k 和整数流 nums 初始化对象。
2、int add(int val) 将 val 插入数据流 nums 后,返回当前数据流中第 k 大的元素。
示例:
输入:
["KthLargest", "add", "add", "add", "add", "add"]
[[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]]
输出:
[null, 4, 5, 5, 8, 8]
解释:
KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]);
kthLargest.add(3); // return 4
kthLargest.add(5); // return 5
kthLargest.add(10); // return 5
kthLargest.add(9); // return 8
kthLargest.add(4); // return 8
|
#基本思路
这题考察优先级队列的使用,可以先做下这道类似的题目 215. 数组中的第 K 个最大元素open in new window。
优先级队列的实现原理详见 图文详解二叉堆,实现优先级队列open in new window。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class KthLargest {
private int k;
private PriorityQueue<Integer> pq = new PriorityQueue<>();
public KthLargest(int k, int[] nums) {
for (int e : nums) {
pq.offer(e);
if (pq.size() > k) {
pq.poll();
}
}
this.k = k;
}
public int add(int val) {
pq.offer(val);
if (pq.size() > k) {
pq.poll();
}
return pq.peek();
}
}
|
给你一个整数数组 nums 和一个整数 k,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入:nums = [1,1,1,2,2,3], k = 2
输出:[1,2]
|
#基本思路
首先,肯定要用一个 valToFreq 哈希表open in new window 把每个元素出现的频率计算出来。
然后,这道题就变成了 215. 数组中的第 K 个最大元素open in new window,只不过第 215 题让你求数组中元素值 e 排在第 k 大的那个元素,这道题让你求数组中元素值 valToFreq[e] 排在前 k 个的元素。
我在 快速排序详解及运用open in new window 中讲过第 215 题,可以用 优先级队列open in new window 或者快速选择算法解决这道题。这里稍微改一下优先级队列的比较函数,或者改一下快速选择算法中的逻辑即可。
这里我再加一种解法,用计数排序的方式找到前 k 个高频元素,见代码。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public int[] topKFrequent(int[] nums, int k) {
HashMap<Integer, Integer> valToFreq = new HashMap<>();
for (int v : nums) {
valToFreq.put(v, valToFreq.getOrDefault(v, 0) + 1);
}
PriorityQueue<Map.Entry<Integer, Integer>>
pq = new PriorityQueue<>((entry1, entry2) -> {
return entry1.getValue().compareTo(entry2.getValue());
});
for (Map.Entry<Integer, Integer> entry : valToFreq.entrySet()) {
pq.offer(entry);
if (pq.size() > k) {
pq.poll();
}
}
int[] res = new int[k];
for (int i = k - 1; i >= 0; i--) {
res[i] = pq.poll().getKey();
}
return res;
}
}
class Solution2 {
public int[] topKFrequent(int[] nums, int k) {
HashMap<Integer, Integer> valToFreq = new HashMap<>();
for (int v : nums) {
valToFreq.put(v, valToFreq.getOrDefault(v, 0) + 1);
}
ArrayList<Integer>[] freqToVals = new ArrayList[nums.length + 1];
for (int val : valToFreq.keySet()) {
int freq = valToFreq.get(val);
if (freqToVals[freq] == null) {
freqToVals[freq] = new ArrayList<>();
}
freqToVals[freq].add(val);
}
int[] res = new int[k];
int p = 0;
for (int i = freqToVals.length - 1; i > 0; i--) {
ArrayList<Integer> valList = freqToVals[i];
if (valList == null) continue;
for (int j = 0; j < valList.size(); j++) {
res[p] = valList.get(j);
p++;
if (p == k) {
return res;
}
}
}
return null;
}
}
|
给定一个单词列表 words 和一个整数 k,返回前 k 个出现次数最多的单词。返回的答案应该按单词出现频率由高到低排序,如果不同的单词有相同出现频率,按字典顺序 排序。
示例 1:
输入:words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出:["i", "love"]
解析:"i" 和 "love" 为出现次数最多的两个单词,均为 2 次。
注意,按字母顺序 "i" 在 "love" 之前。
|
#基本思路
这道题可以认为是 347. 前 K 个高频元素open in new window 的进阶版。整体思路还哈希表计数,然后用 优先级队列open in new window 维护出现频率最高的 k 个单词。
只是我们需要注意题目要求,在 PriorityQueue 的比较器中正确处理频率相同的单词的字典序。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public List<String> topKFrequent(String[] words, int k) {
HashMap<String, Integer> wordToFreq = new HashMap<>();
for (String word : words) {
wordToFreq.put(word, wordToFreq.getOrDefault(word, 0) + 1);
}
PriorityQueue<Map.Entry<String, Integer>> pq = new PriorityQueue<>(
(entry1, entry2) -> {
if (entry1.getValue().equals(entry2.getValue())) {
return entry2.getKey().compareTo(entry1.getKey());
}
return entry1.getValue().compareTo(entry2.getValue());
});
for (Map.Entry<String, Integer> entry : wordToFreq.entrySet()) {
pq.offer(entry);
if (pq.size() > k) {
pq.poll();
}
}
LinkedList<String> res = new LinkedList<>();
while (!pq.isEmpty()) {
res.addFirst(pq.poll().getKey());
}
return res;
}
}
|
最后,再看一看优先级队列的其他运用吧:
请你设计一个管理 n 个座位预约的系统,座位编号从 1 到 n。
请你实现 SeatManager 类:
SeatManager(int n) 初始化一个 SeatManager 对象,它管理从 1 到 n 编号的 n 个座位。所有座位初始都是可预约的。int reserve() 返回可以预约座位的最小编号,此座位变为不可预约。void unreserve(int seatNumber) 将给定编号 seatNumber 对应的座位变成可以预约。
示例 1:
输入:
["SeatManager", "reserve", "reserve", "unreserve", "reserve", "reserve", "reserve", "reserve", "unreserve"]
[[5], [], [], [2], [], [], [], [], [5]]
输出:
[null, 1, 2, null, 2, 3, 4, 5, null]
解释:
SeatManager seatManager = new SeatManager(5); // 初始化 SeatManager,有 5 个座位。
seatManager.reserve(); // 所有座位都可以预约,所以返回最小编号的座位,也就是 1。
seatManager.reserve(); // 可以预约的座位为 [2,3,4,5],返回最小编号的座位,也就是 2。
seatManager.unreserve(2); // 将座位 2 变为可以预约,现在可预约的座位为 [2,3,4,5]。
seatManager.reserve(); // 可以预约的座位为 [2,3,4,5],返回最小编号的座位,也就是 2。
seatManager.reserve(); // 可以预约的座位为 [3,4,5],返回最小编号的座位,也就是 3。
seatManager.reserve(); // 可以预约的座位为 [4,5],返回最小编号的座位,也就是 4。
seatManager.reserve(); // 唯一可以预约的是座位 5,所以返回 5。
seatManager.unreserve(5); // 将座位 5 变为可以预约,现在可预约的座位为 [5]。
|
#基本思路
这题是 379. 电话目录管理系统open in new window 的进阶版,那一道题返回的空闲号码可以随意,而这道题要求返回最小的座位编号。
其实很思路是一样的,只是这里需要用到能够按照元素大小自动排序的数据结构 优先级队列(二叉堆)open in new window,直接看代码吧。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class SeatManager {
PriorityQueue<Integer> pq = new PriorityQueue<>();
public SeatManager(int n) {
for (int i = 1; i <= n; i++) {
pq.offer(i);
}
}
public int reserve() {
return pq.poll();
}
public void unreserve(int i) {
pq.offer(i);
}
}
|
中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
设计一个支持以下两种操作的数据结构:
1、void addNum(int num) 从数据流中添加一个整数到数据结构中。
2、double findMedian() 返回目前所有元素的中位数。
示例:
addNum(1)
addNum(2)
findMedian() -> 1.5
addNum(3)
findMedian() -> 2
|
#基本思路
本题的核心思路是使用两个优先级队列。
小的倒三角就是个大顶堆,梯形就是个小顶堆,中位数可以通过它们的堆顶元素算出来:
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class MedianFinder {
private PriorityQueue<Integer> large;
private PriorityQueue<Integer> small;
public MedianFinder() {
large = new PriorityQueue<>();
small = new PriorityQueue<>((a, b) -> {
return b - a;
});
}
public double findMedian() {
if (large.size() < small.size()) {
return small.peek();
} else if (large.size() > small.size()) {
return large.peek();
}
return (large.peek() + small.peek()) / 2.0;
}
public void addNum(int num) {
if (small.size() >= large.size()) {
small.offer(num);
large.offer(small.poll());
} else {
large.offer(num);
small.offer(large.poll());
}
}
}
|
给定两个大小相等的数组 A 和 B,A 相对于 B 的优势可以用满足 A[i] > B[i] 的索引 i 的数目来描述。
请你返回 A 的任意排列,使其相对于 B 的优势最大化。
示例 1:
输入:A = [2,7,11,15], B = [1,10,4,11]
输出:[2,11,7,15]
|
#基本思路
这题就像田忌赛马的情景,nums1 就是田忌的马,nums2 就是齐王的马,数组中的元素就是马的战斗力,你就是谋士孙膑,请你帮田忌安排赛马顺序,使胜场最多。
最优策略是将齐王和田忌的马按照战斗力排序,然后按照战斗力排名一一对比:
如果田忌的马能赢,那就比赛,如果赢不了,那就换个垫底的来送人头,保存实力。
具体分析见详细题解。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public int[] advantageCount(int[] nums1, int[] nums2) {
int n = nums1.length;
PriorityQueue<int[]> maxpq = new PriorityQueue<>(
(int[] pair1, int[] pair2) -> {
return pair2[1] - pair1[1];
}
);
for (int i = 0; i < n; i++) {
maxpq.offer(new int[]{i, nums2[i]});
}
Arrays.sort(nums1);
int left = 0, right = n - 1;
int[] res = new int[n];
while (!maxpq.isEmpty()) {
int[] pair = maxpq.poll();
int i = pair[0], maxval = pair[1];
if (maxval < nums1[right]) {
res[i] = nums1[right];
right--;
} else {
res[i] = nums1[left];
left++;
}
}
return res;
}
}
|
给你一个二维数组 tasks,用于表示 n 项从 0 到 n - 1 编号的任务。其中 tasks[i] = [enqueueTime_i, processingTime_i] 意味着第 i 项任务将会于 enqueueTime_i 时进入任务队列,需要 processingTime_i 的时长完成执行。
现有一个单线程 CPU,同一时间只能执行 最多一项 任务,该 CPU 将会按照下述方式运行:
- 如果 CPU 空闲,且任务队列中没有需要执行的任务,则 CPU 保持空闲状态。
- 如果 CPU 空闲,但任务队列中有需要执行的任务,则 CPU 将会选择执行时间最短的任务开始执行。如果多个任务具有同样的最短执行时间,则选择下标最小的任务开始执行。
- 一旦某项任务开始执行,CPU 在 执行完整个任务 前都不会停止。
- CPU 可以在完成一项任务后,立即开始执行一项新任务。
返回 CPU 处理任务的顺序。
示例 1:
输入:tasks = [[1,2],[2,4],[3,2],[4,1]]
输出:[0,2,3,1]
解释:事件按下述流程运行:
- time = 1,任务 0 进入任务队列,可执行任务项 = {0}
- 同样在 time = 1,空闲状态的 CPU 开始执行任务 0,可执行任务项 = {}
- time = 2,任务 1 进入任务队列,可执行任务项 = {1}
- time = 3,任务 2 进入任务队列,可执行任务项 = {1, 2}
- 同样在 time = 3,CPU 完成任务 0 并开始执行队列中用时最短的任务 2,可执行任务项 = {1}
- time = 4,任务 3 进入任务队列,可执行任务项 = {1, 3}
- time = 5,CPU 完成任务 2 并开始执行队列中用时最短的任务 3,可执行任务项 = {1}
- time = 6,CPU 完成任务 3 并开始执行任务 1,可执行任务项 = {}
- time = 10,CPU 完成任务 1 并进入空闲状态
|
#基本思路
这题的难度不算大,就是有些复杂,难点在于你要同时控制三个变量(开始时间、处理时间、索引)的有序性,而且这三个变量还有优先级:
首先应该考虑开始时间,因为只要到了开始时间,任务才进入可执行状态;
其次应该考虑任务的处理时间,在所有可以执行的任务中优先选择处理时间最短的;
如果存在处理时间相同的任务,那么优先选择索引最小的。
所以这道题的思路是:
先根据任务「开始时间」排序,维护一个时间线变量 now 来判断哪些任务到了可执行状态,然后借助一个优先级队列 pq 对「处理时间」和「索引」进行动态排序。
利用优先级队列动态排序是有必要的,因为每完成一个任务,时间线 now 就要更新,进而产生新的可执行任务。
#解法代码
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
class Solution {
public int[] getOrder(int[][] tasks) {
int n = tasks.length;
ArrayList<int[]> triples = new ArrayList<>();
for (int i = 0; i < tasks.length; i++) {
triples.add(new int[]{tasks[i][0], tasks[i][1], i});
}
triples.sort((a, b) -> {
return a[0] - b[0];
});
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> {
if (a[1] != b[1]) {
return a[1] - b[1];
}
return a[2] - b[2];
});
ArrayList<Integer> res = new ArrayList<>();
int now = 0;
int i = 0;
while (res.size() < n) {
if (!pq.isEmpty()) {
int[] triple = pq.poll();
res.add(triple[2]);
now += triple[1];
} else if (i < n && triples.get(i)[0] > now) {
now = triples.get(i)[0];
}
for (; i < n && triples.get(i)[0] <= now; i++) {
pq.offer(triples.get(i));
}
}
int[] arr = new int[n];
for (int j = 0; j < n; j++) {
arr[j] = res.get(j);
}
return arr;
}
}
|